
Aunque como vimos en un artículo anterior la investigación en redes neuronales no es para nada nuevo, y llevan aplicándose en sistemas de computación desde los 60, lo cierto es que la Inteligencia Artificial (IA) es un concepto todavía difuso, es por eso que en un intento de branding y diferenciación se estén generando nuevos términos relacionados con la IA constantemente: machine intelligence, computación cognitiva o sensitiva, intelligent computing,… Lo cual ayuda en más bien poco a clarificar la escena actual. Existen dos grandes escuelas de pensamiento para hacer análisis. Por un lado, la rama de la estadística, como la bayesiana, basados en métodos de modelado centrados en la obtención de insights como modelos de regresión lineal. Y por otro lado, la escuela conexionista, basada en redes neuronales, centrados en el poder predictivo del Deep Learning o «aprendizaje profundo». Con la inferencia profunda (los datos son nos estructurados, necesitan un algoritmo para extraer los datos válidos) se podrían mezclar ambas corrientes.
La mayoría de casos cuando se habla de IA se trata de la aplicación de un conjunto de modelos de machine learning o aprendizaje automático y predictivo, una forma de IA «débil» enfocada a tareas muy específicas como reconocimiento de voz o procesamiento de lenguaje natural, muy diferente de la Inteligencia Artificial genérica de la que llevan advirtiendo figuras como Stephen Hawking, Steve Wozniak, Bill Gates o Elon Musk con su frase «con IA estamos llamando al demonio».
¿Qué es Deep Learning?
En realidad cuando hablamos de Inteligencia Artificial estamos generalmente hablando de redes neuronales artificiales y Deep Learning. El Deep Learning es un tipo de algoritmos de aprendizaje automático estructurado o jerárquico, dicho de otra forma, tomar modelos existentes para predecir el futuro con los datos disponibles. El proceso de predicción se realiza mediante el aprendizaje, no con reglas programadas previamente. Casi siempre ligado al procesamiento de texto, voz, imagen y vídeo. Para el ML (machine learning) se usan una serie de capas de unidades de procesamiento no lineales para la extracción y transformación de características. Cada capa emplea como input el resultado o output de la capa anterior. Los algoritmos pueden ser supervisados o no supervisados y los tipos de aplicaciones pueden ser análisis de patrones (aprendizaje no supervisado) y de clasificación (aprendizaje supervisado).
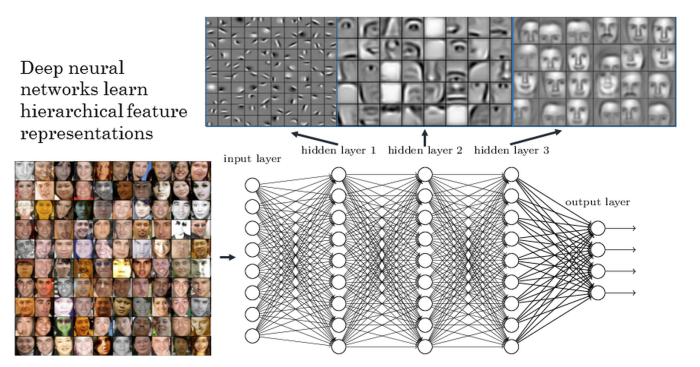
En una red profunda (deep network) son muchas las capas en las que la señal va modificándose y pasando sucesivamente, permitiendo al algoritmo utilizar múltiples capas de procesamiento, compuestas de múltiples transformaciones lineales y no lineales. Por ejemplo, antes de que existieran estas técnicas si quisiéramos que para nuestra aplicación el sistema reconociera una naranja habría que programar el software dándole una serie de instrucciones: tiene que ser de forma redonda, ciertas medidas, y hasta cierto punto funcionaba pero llega un momento que si queremos que el reconocimiento sea más eficaz o que lo hiciera para cualquier objeto o entidad habría que programar tal cantidad de reglas que sería casi imposible. Gracias al Deep Learning, una rama de machine learning, podemos hacerlo mucho más rápidamente y con mejores resultados aplicando una red neuronal a un gigantesco conjunto de datos. Básicamente le enseñamos un resultado y le dejamos que replique los resultados para aprender los pasos para llegar a ese objetivo, automatizando así la tarea de entrenamiento. Los estilos de entrenamiento pueden ser supervisados, no supervisados y entrenamiento de refuerzo.
Estas técnicas de machine learning han contribuido al desarrollo del interfaz conversacional que va a provocar pronto un cambio radical en cómo nos comunicaremos con los dispositivos. Sobre esto puedes saber más buscando interfaces naturales o Zero UIs.
Tipos de redes neuronales
Según el objetivo que persigamos, se aplican en diversos campos como visión por ordenador, reconocimiento automático del habla, NLP (procesamiento del lenguaje natural), reconocimiento de audio y en la bioinformática, podremos emplear diferentes tipos de arquitecturas deep learning. Hay muchas variedades pero por no extendernos vamos a resumir las más utilizadas:
- redes neuronales profundas que hemos comentado anteriormente.
- redes convolucionales. Son muy eficaces para procesar datos visuales y otros datos bidimensionales.
- redes de creencias profundas. Un modelo probabilístico y generativo compuesto de múltiples capas de unidades ocultas. Se puede considerar como una composición de simples módulos de aprendizaje que componen cada capa.
- redes neuronales recurrentes. Las conexiones entre unidades forman un ciclo dirigido. Pueden usar su memoria interna para procesar secuencias arbitrarias de inputs. Esto los hace aplicables a tareas tales como reconocimiento de escritura o reconocimiento de voz.
Usos de Deep Learning
 El aprendizaje profundo y los modelos predictivos jerárquicos han tenido su mayor uso en el área de los diagnósticos médicos y en análisis predictivos en los mercados financieros pero están adquiriendo cada vez mayor peso en el resto de sectores como componentes esenciales para aplicaciones como sistemas de recomendación, detección de fraude, predicción de churn y modelos de propensión, detección de anomalías y auditoría de datos. Es paradigmático el caso de Google, donde su propio CEO reconoció no ver venir la avalancha del movimiento de Machine Intelligence ni su potencial y ahora es un componente nuclear que aplican en prácticamente todos sus productos, y que usamos todos diariamente. Las Smart Replies de Gmail, el reconocimiento de voz de Google Now, las traducciones semánticas y no literales de Google Translate, la búsqueda por cualquier concepto en Google Photos, las rutas recomendadas en Google Maps, o el sistema de publicación programática de Adwords son todas nuevas funcionalidades creadas gracias a la aplicación de Deep Learning en sus productos.
El aprendizaje profundo y los modelos predictivos jerárquicos han tenido su mayor uso en el área de los diagnósticos médicos y en análisis predictivos en los mercados financieros pero están adquiriendo cada vez mayor peso en el resto de sectores como componentes esenciales para aplicaciones como sistemas de recomendación, detección de fraude, predicción de churn y modelos de propensión, detección de anomalías y auditoría de datos. Es paradigmático el caso de Google, donde su propio CEO reconoció no ver venir la avalancha del movimiento de Machine Intelligence ni su potencial y ahora es un componente nuclear que aplican en prácticamente todos sus productos, y que usamos todos diariamente. Las Smart Replies de Gmail, el reconocimiento de voz de Google Now, las traducciones semánticas y no literales de Google Translate, la búsqueda por cualquier concepto en Google Photos, las rutas recomendadas en Google Maps, o el sistema de publicación programática de Adwords son todas nuevas funcionalidades creadas gracias a la aplicación de Deep Learning en sus productos.
Los gigantes de Internet han acelerado la actualización de su oferta de servicios con diferentes grados de aprendizaje automático que pueden ser adquiridos as-a-service en modo cloud: Google Cloud ML, Microsoft Cognitive Services, Intel Deep Learning, Amazon AI services.
Baidu, Facebook, Apple,…. todas las grandes tecnológicas están apostando muy fuerte por tomar la iniciativa y no quedarse atrás. Facebook está formando a todos sus ingenieros en machine learning y han lanzado un programa para convertirse en investigadores de Inteligencia Artificial a tiempo completo. Google lleva meses impartiendo clases internas entre sus empleados en el manejo del deep learning.
Qué necesito para Deep Learning
Las redes neuronales artificiales son superiores a los modelos de machine learning en la mayoría de casos ya que son más automatizadas, pero tienen una serie de requisitos para que funcionen. Uno de los requerimientos para que el deep learning funcione con precisión es invertir en los algoritmos mucho tiempo de entrenamiento y con grandes volúmenes de datos, es por eso que ha ido de la mano siempre de los avances en big data y en hardware. También requieren gran potencia de cálculo. Se ha demostrado que gracias a los avances en las GPU se ha conseguido acelerar los algoritmos de entrenamiento en muchos órdenes de magnitud, bajando de semanas a días los tiempos de entrenamiento.
Software para Deep Learning
Prácticamente todas las librerías para machine learning están disponibles en open source. SciKi Learn, TensorFlow (el framework adquirido por Google con APIs para C++ y Python), H2O, Keras (framework deep learning en Python), Theano (librería ML), Microsoft CNTK (para Windows y Linux), Caffe, Torch (librería ML que usa Facebook). Cada uno tiene sus pros y contras. En otro artículo próximo describiremos los puntos fuertes y mejores usos de cada framework.


