El procesamiento del lenguaje natural (PLN) intenta emular los diferentes idiomas humanos, a través de varias técnicas de inteligencia artificial. Por «lenguaje natural» entendemos aquel que usas a diario para la comunicación cotidiana: el inglés, el español, el portugués…
A diferencia de los lenguajes artificiales, como son los lenguajes de programación y las anotaciones matemáticas, los naturales han evolucionado a medida que ha pasado el tiempo y, actualmente, son procesados con diversas herramientas informáticas como es Python.
Procesamiento del Lenguaje Natural (PLN)

El procesamiento del lenguaje natural es una rama de la inteligencia artificial que se ocupa de la interacción entre los ordenadores y los seres humanos usando el lenguaje natural.
Tiene como principal objetivo dar sentido a los idiomas humanos a través de la computación, de manera que sea entendible. La mayoría de las técnicas de PLN se basan en el aprendizaje automático para ser capaz de comprender y dar sentido al significado de los diferentes idiomas que existen.
A continuación, un ejemplo de una interacción entre humanos y máquinas utilizando el procesamiento del lenguaje natural:
- La persona habla con la máquina.
- La máquina captura el audio.
- Se lleva a cabo la conversión de audio a texto.
- Procesamiento de los datos del texto.
- Tiene lugar la conversión de datos a audio.
- La máquina responde a la persona reproduciendo el archivo de audio.
El gran desafío
PLN es considerado uno de los grandes retos de la inteligencia artificial ya que es una de las tareas más complicadas y desafiantes: ¿cómo comprender realmente el significado de un texto? ¿cómo intuir neologísmos, irónias, chistes o poesía? No es suficiente con comprender palabras, se deberá comprender al conjunto de palabras que conforman una oración, y al conjunto de lineas que comprenden un párrafo. Dando un sentido global al análisis del texto/discurso para poder sacar buenas conclusiones.

Nuestro lenguaje está lleno de ambigüedades, de palabras con distintas acepciones, giros y diversos significados según el contexto. Esto hace que el PLN sea una de las tareas más difíciles de dominar.
Usos del PLN
- Resumen de textos, consiste en encontrar la idea principal del texto e ignorar lo que no sea relevante.
- ChatBots, deberán ser capaces de mantener una charla fluida con el usuario y responder a sus preguntas de manera automática.
- Generación automática de keywords y generación de textos
- Reconocimiento de entidades, encontrar personas, entidades comerciales o gubernamentales, países, ciudades, marcas…etc.
- Análisis de sentimientos, deberá comprender si un tweet, una review o comentario es positivo o negativo y en qué magnitud (neutro). Muy utilizado en redes sociales, en política, opiniones de productos y en motores de recomendación.
- Machine Translation, Ofrece la posibilidad traducir el texto o el audio de un idioma a otro rápidamente y cada vez con más exactitud.
- Clasificación automática de textos, en categorías pre-existentes, detectar temas recurrentes y crear las categorías.
Beneficios
Automatización de tareas
Permite organizar tareas para que se realicen automáticamente, realizando una búsqueda, clasificación y análisis mucho más rápida y exhaustiva. Esto ayuda a que el profesional que se encargaba de estas tareas pueda realizar otras.
Hace tareas que son casi imposibles por su volumen
Se encarga de tareas que serían muy complicadas de llevarse a cabo solo por humanos, o que tardarían mucho en completarlas debido a su gran extensión. De esta forma se ahorra bastante dinero de la inversión que sería necesaria para contratar a todo el personal.
Técnicas comunes
- Tokenizar: separar palabras del texto en entidades llamadas tokens, con las que trabajaremos luego. Deberemos pensar si utilizaremos los signos de puntuación como token, si daremos importancia o no a las mayúsculas y si unificamos palabras similares en un mismo token.
- Tagging Part of Speech (PoS): Clasificar las oraciones en verbo, sustantivo, adjetivo preposición, etc.

- Shallow parsing / Chunks: Sirve para entender la gramática en las oraciones. Se hace un parseo de los tokens y a partir de su PoS se arma un árbol de la estructura.
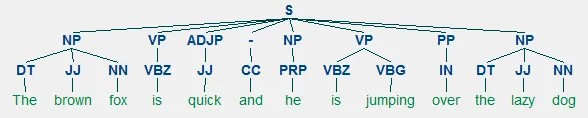
- Significado de las palabras: semántica…
- Pragmatic Analysis: detectar cómo se dicen las cosas: ironía, sarcasmo, intencionalidad, etc
- Bag of words: es una manera de representar el vocabulario que utilizaremos en nuestro modelo y consiste en crear una matriz en la que cada columna es un token y se contabilizará la cantidad de veces que aparece ese token en cada oración (representadas en cada fila).
- word2vec: Es una técnica que aprende de leer enormes cantidades de textos y memorizar qué palabras parecen ser similares en diversos contextos. Luego de entrenar suficientes datos, se generan vectores de 300 dimensiones para cada palabra conformando un nuevo vocabulario en donde las palabras “similares” se ubican cercanas unas de otras. Utilizando vectores pre-entrenados, logramos tener muchísima riqueza de información para comprender el significado semántico de los textos.
Python y PLN
NLTK es la biblioteca más popular para el procesamiento del PLN, está escrita en Python y tiene a una gran comunidad detrás. Una de las ventajas del NLTK es su facilidad, de hecho, es la biblioteca más sencilla de usar de todas las que existen.
Por otra parte, esta plataforma proporciona interfaces a más de cincuenta recursos corporales y léxicos, como puede ser WordNet, a lo que se suman varias bibliotecas de procesamiento de texto para la tokenización, el etiquetado, la clasificación, la derivación, el razonamiento semántico, los análisis envoltorios para bibliotecas PLN con aplicaciones industriales y, además, un completo foro de discusiones entre usuarios.
Gracias a una guía práctica que presenta los fundamentos de la programación junto con temas de lingüística computacional, además de documentación API completa, NLTK está especialmente indicado para lingüistas, estudiantes, ingenieros, educadores, usuarios de la industria en general e investigadores. Por otra parte, la biblioteca está disponible para Mac OS X, Windows y Linux. Además, no hay que olvidar que NLTK es un proyecto gratuito, open source y, por tanto, dirigido por la comunidad.
En conclusión, el PLN se ha convertido en una de las principales herramientas para dotar de Inteligencia Artificial a los objetos.
Esta es la principal tendencia tecnológica del mercado, que ya está presente en dispositivos tales como altavoces inteligentes, smartphones, vehículos, etc., y se está ampliando cada vez más dada su gran aceptación por parte de los usuarios. El procesamiento de lenguaje natural tiene un gran aliado en el lenguaje de programación de código abierto Python.
Herramientas de Python para PLN
- NLTK: Esta es la lib con la que todos empiezan, sirve mucho para pre-procesamiento, crear los tokens, stemming, POS tagging, etc
- TextBlob: fue creada encima de NLYK y es fácil de usar. Incluye algunas funcionalidades adicionales como análisis de sentimiento y spell check.
- Gensim: contruida específicamente para modelado de temas e incluye multiples técnicas (LDA y LSI). También calcula similitud de documentos.
- SpaCy: Puede hacer muchísimas cosas al estilo de NLTK pero es bastante más rápido.
- WebScraping: Obtener textos desde diversas páginas webs
Empresas que utilizan PLN
Todos tenemos claro que el procesamiento de lenguaje natural es una de las áreas de la inteligencia artificial que más utilidad tiene para las empresas, a continuación te damos algunos ejemplos de start ups que lo utilizan sus proyectos:
- MarketMuse
- Klevu
- English Central
- Kngine
- Desti
- MindMeld
- Yummly
- Agolo
Casos de éxito
GPT – 3
GPT-3, es un modelo de lenguaje autorregresivo que utiliza el aprendizaje profundo para producir texto similar al de un humano. Es el modelo de predicción de lenguaje de tercera generación de la serie GPT-n creada por OpenAI, un laboratorio de investigación de inteligencia artificial con sede en San Francisco.
La versión completa de GPT-3 tiene una capacidad de 175 mil millones de parámetros de aprendizaje automático, que es más de dos órdenes de magnitud mayor que la de su predecesor, GPT-2.
GPT-3, que se introdujo en Mayo de 2020 y se encuentra en prueba beta a partir de julio de 2020, es parte de una tendencia en los sistemas de procesamiento del lenguaje natural (PLN) de representaciones de lenguaje previamente entrenadas. Antes del lanzamiento de GPT-3, el modelo de lenguaje más grande era Turing NLG de Microsoft, presentado en febrero de 2020, con una capacidad diez veces menor que la de GPT-3.
Google Bert
BERT es el acrónimo para Bidirectional Encoder Representations from Transformers (Representaciones de Codificador Bidireccional de Transformadores). Se trata de un sistema basado en inteligencia artificial (IA) para ayudar a los algoritmos de Google Search a entender mejor el lenguaje que utilizamos los usuarios en el momento de realizar una búsqueda mediante oraciones.
En este sentido, la nueva actualización en los algoritmos de Google es tan innovadora como la realizada en 2015 con RankBrain, el primer mecanismo de IA utilizado para analizar las consultas de los usuarios y clasificar mejor los resultados en las SERP. Ambos sistemas, BERT en mayor medida, aplican un método de análisis que permite contextualizar de forma más natural cada consulta.
BERT posee una característica que se llama “bidireccionalidad”, que consiste en analizar una oración en dos direcciones. Es decir, analiza las palabras que se encuentran tanto a la izquierda como a la derecha de una palabra clave, y esto le permite entender en profundidad el contexto y la temática de toda la frase que introduce un usuario para la búsqueda en Google. De esta manera, después de comprender muy bien de qué trata determinada consulta, los algoritmos de Google, gracias a sus más de 200 factores de clasificación, seleccionan aquellos contenidos que mejor responden a esa búsqueda, con lo cual los resultados en las SERP se vuelven cada vez más relevantes para los usuarios.
Text to Text
VODAFONE
Vodafone es el claro ejemplo de una compañía pionera en el uso de la Inteligencia Artificial y el Lenguaje Natural en su contact center. La empresa telefónica, que ya había experimentado resultados muy positivos tras la instalación de un Voicebot en su contact center y un bot en su aplicación, ha querido sumar un canal de contacto más mediante la instalación de un bot de texto en WhatsApp para mejorar la experiencia de sus clientes, acercarse a ellos y ampliar su capacidad de autogestión.
Speech to Speech
CASER SEGUROS
Caser es el claro ejemplo de una aseguradora que ha aprovechado la ola de transformación digital para mejorar la experiencia de sus clientes y optimizar el trabajo de sus gestores con la modernización de su anterior IVR incorporando el reconocimiento de lenguaje natural (NLP), pregunta abierta y la implementación de autogestiones telefónicas en el nuevo Voicebot, así como la creación de un chatbot interno para mediadores.
VODAFONE
MyVoice es el proyecto que ha permitido redefinir el VoiceBot de Vodafone modernizando su interfaz para acercarla aún más al cliente, hacerlo inteligible, confiable y empático.
Conclusión
Vivimos en un mundo en el cual seguramente los humanos nos diferenciemos de otras especies por haber desarrollado herramientas de manera eficiente como el lenguaje. Nos comunicamos constantemente, hablando, con palabras, con gestos. Estamos rodeados de símbolos, de carteles, de indicaciones, de unos y ceros. El NLP es una herramienta fundamental que deberemos aprender y dominar para poder capacitar a nuestras máquinas y volverlas mucho más versátiles al momento de interactuar con el entorno, dando capacidad de comprender mejor, de explicarse: de comunicarse.
Debemos ser capaces de entender las diversas herramientas y técnicas utilizadas en NLP y saber utilizarlas para resolver el problema adecuado. El NLP abarca muchísimo espectro y es un recorrido que comienza pero nunca acaba… siguen apareciendo nuevos papers y nuevos instrumentos de acción. Al combinar estas técnicas de NLP “tradicional” con Deep Learning, la combinatoria de nuevas posibilidades es exponencial.


