
Antes del BI (Inteligencia de negocio) el análisis de datos era conocido como decision support (soporte a las decisiones). Consistía en un análisis descriptivo de la situación en base a datos históricos almacenados de forma estructurada normalmente en sistemas monolíticos aplicando técnicas OLAP (Online Analytical Processing). En esta primera etapa tradicionalmente podemos dar respuesta manualmente a qué es lo que ha pasado. Condensando datos estructurados para ser entendidos por las personas mediante visualizaciones podemos referirnos a cualquier evento pasado que tengamos registrado.
El siguiente paso en el camino para llegar a ser verdaderamente una compañía data driven pasa por el análisis predictivo (predictive analytics) y cognitivo. Es la diferencia entre tener una actitud reactiva, en la que muchas veces es tarde para actuar, y pasar a una forma proactiva de trabajar, anticipándonos a eventos, tendencias y al mercado.
¿Qué se entiende por predictive analytics?
El análisis predictivo es un término paraguas para referirnos al conjunto de procesos que implican aplicar diferentes técnicas computacionales con el objetivo de realizar predicciones sobre el futuro basándonos en datos pasados. Las variedad de técnicas empleadas incluyen minería de datos (data mining), modelado, reconocimiento de patrones, graph analytics, …
¿Podemos predecir el futuro?
Los modelos predictivos aplican resultados conocidos con el fin de entrenar al modelo para predecir valores, con datos diferentes o completamente nuevos, en un proceso repetitivo. El modelado proporciona los resultados en forma de predicciones representadas mediante el grado de probabilidad de la variable objetivo basado en la significación estimada a partir de un conjunto de variables de entrada. La variable objetivo puede tratarse de las ventas, la cara de una persona, las coordenadas de un yacimiento petrolífero, o cualquier cosa que se nos ocurra.
Realmente no existe limitación en los usos de aplicar predictive analytics, dependerán de qué queremos obtener. Se aplican ampliamente en casi cualquier sector, no sólo de negocio, ya sea para detectar oportunidades comerciales, detectar y reducir fraude, retención de clientes, predecir fallos en sistemas, sino también en otros campos en los que todos nos beneficiamos como detectar cáncer en pacientes, evolución de epidemias, ahorro de costes en organismos públicos, reconocimiento del habla, la lista es interminable. Podemos eso sí clasificar los tipos de análisis predictivo y las técnicas más adecuadas para conseguir los objetivos.
Tipos de análisis predictivo
Como hemos dicho los modelos predictivos son distintos de los descriptivos, que nos ayudan a comprender qué ha sucedido, o de los modelos de diagnóstico, que nos ayudan a la hora de entender las relaciones entre entidades con el fin de averiguar porqué algo ha sucedido. Hay dos tipos de modelos predictivos: modelos de clasificación y de regresión. Los modelos de clasificación permiten predecir la pertenencia a una clase. Por ejemplo, si tratamos de clasificar entre nuestros clientes quiénes son más propensos a abandonar. Para ello se establecen variables de entrada como el riesgo de crédito, respuestas a comunicaciones, etc. Los resultados del modelo son binarios, o un sí o un no (en forma de 0 y 1) con su grado de probabilidad. Los modelos de regresión en cambio nos permiten predecir un valor. Por ejemplo, cual es el beneficio de un determinado cliente (o segmento) en los próximos meses.
Técnicas de análisis predictivo
Por orden descendente de uso las técnicas de modelado de análisis predictivo más aplicadas son:
Árboles de decisión
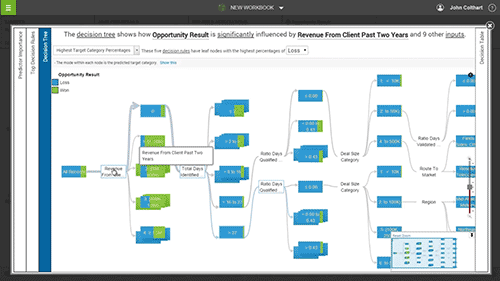 Son modelos de clasificación que dividen los datos en subconjuntos basados en categorías de variables de entrada. Esto es de gran ayuda a la hora de determinar las decisiones a lo largo del camino (funnel de compra por ejemplo). Los árboles de decisión tienen la forma de un árbol en el que cada rama representa una elección entre el número de alternativas, y cada hoja representa una clasificación o decisión. Este es un modelo que al buscar en los datos trata de encontrar la variable que permita dividir el dataset en grupos lógicos que son más diferentes entre sí. Se usan bastante porque son fáciles de entender e interpretar. Permite controlar bien los valores que faltan y son útiles para la selección preliminar de variables. Así que si tienes un montón de valores vacíos o quieres una respuesta rápida y sencilla puedes comenzar con un árbol de decisión.
Son modelos de clasificación que dividen los datos en subconjuntos basados en categorías de variables de entrada. Esto es de gran ayuda a la hora de determinar las decisiones a lo largo del camino (funnel de compra por ejemplo). Los árboles de decisión tienen la forma de un árbol en el que cada rama representa una elección entre el número de alternativas, y cada hoja representa una clasificación o decisión. Este es un modelo que al buscar en los datos trata de encontrar la variable que permita dividir el dataset en grupos lógicos que son más diferentes entre sí. Se usan bastante porque son fáciles de entender e interpretar. Permite controlar bien los valores que faltan y son útiles para la selección preliminar de variables. Así que si tienes un montón de valores vacíos o quieres una respuesta rápida y sencilla puedes comenzar con un árbol de decisión.
Regresión lineal y logística
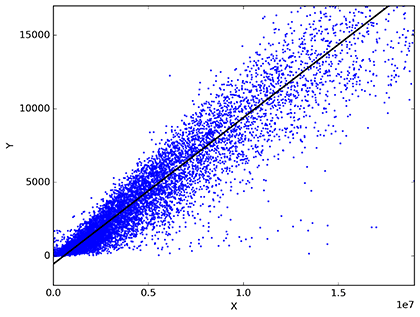 Es uno de los métodos más empleados en estadística. Los análisis de regresión estiman las relaciones entre variables. Esta técnica es apropiada cuando podemos asumir que los datos continuos siguen una distribución normal, encuentra patrones clave en grandes conjuntos de datos, y se utiliza a menudo para determinar cuánto influyen en el movimiento de un activo factores específicos, como por ejemplo el precio de un producto. En un análisis de regresión lo que queremos es predecir un valor (representada en la variable dependiente Y). En una regresión lineal se emplea una variable independiente para explicar o predecir el resultado (Y), mientras que en una regresión múltiple se usan dos o más variables independientes. Las regresiones logísticas son utilizadas para predecir el resultado de una variable categórica (una variable que puede adoptar un número limitado de categorías) en función de las variables independientes o predictoras. Es útil para modelar la probabilidad de un evento ocurriendo como función de otros factores. La variable de respuesta es categórica, lo que significa que puede asumir sólo un número limitado de valores.
Es uno de los métodos más empleados en estadística. Los análisis de regresión estiman las relaciones entre variables. Esta técnica es apropiada cuando podemos asumir que los datos continuos siguen una distribución normal, encuentra patrones clave en grandes conjuntos de datos, y se utiliza a menudo para determinar cuánto influyen en el movimiento de un activo factores específicos, como por ejemplo el precio de un producto. En un análisis de regresión lo que queremos es predecir un valor (representada en la variable dependiente Y). En una regresión lineal se emplea una variable independiente para explicar o predecir el resultado (Y), mientras que en una regresión múltiple se usan dos o más variables independientes. Las regresiones logísticas son utilizadas para predecir el resultado de una variable categórica (una variable que puede adoptar un número limitado de categorías) en función de las variables independientes o predictoras. Es útil para modelar la probabilidad de un evento ocurriendo como función de otros factores. La variable de respuesta es categórica, lo que significa que puede asumir sólo un número limitado de valores.
Redes neuronales
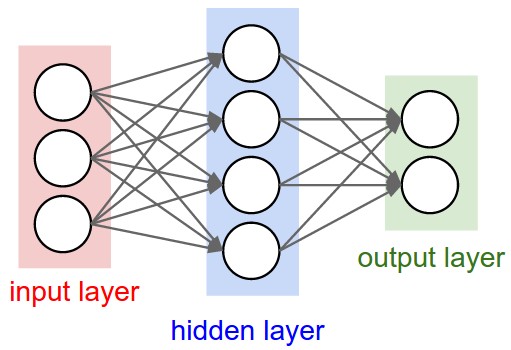 Y llegamos a las más de moda con el reciente auge de la Inteligencia Artificial y Deep Learning, las redes neuronales consisten en técnicas sofisticadas capaces de modelar relaciones extremadamente complejas. Se han hecho populares porque son muy potentes pero flexibles al mismo tiempo. Tienen la capacidad de manejar relaciones no lineales de los datos, lo que lo hace muy interesante cuantos más datos manejemos, ideal para el análisis de big data. Otras veces se usan simplemente para confirmar descubrimientos de otras técnicas más sencillas como las regresiones o los árboles de decisión. Las redes neuronales se basan en el reconocimiento de patrones y en algunos procesos «artificialmente inteligentes» que permiten modelar gráficamente los parámetros. Funcionan muy bien cuando no tenemos fórmula matemática conocida que relacione los inputs y outputs, en este sentido la predicción es más importante que la explicación. Y necesitan eso sí, grandes cantidades de datos de entrenamiento para que resulten fiables. Como explicamos en un artículo previo, las redes reuronales artificiales fueron desarrolladas por investigadores que trataban de imitar el comportamiento neurofisiológico del cerebro humano.
Y llegamos a las más de moda con el reciente auge de la Inteligencia Artificial y Deep Learning, las redes neuronales consisten en técnicas sofisticadas capaces de modelar relaciones extremadamente complejas. Se han hecho populares porque son muy potentes pero flexibles al mismo tiempo. Tienen la capacidad de manejar relaciones no lineales de los datos, lo que lo hace muy interesante cuantos más datos manejemos, ideal para el análisis de big data. Otras veces se usan simplemente para confirmar descubrimientos de otras técnicas más sencillas como las regresiones o los árboles de decisión. Las redes neuronales se basan en el reconocimiento de patrones y en algunos procesos «artificialmente inteligentes» que permiten modelar gráficamente los parámetros. Funcionan muy bien cuando no tenemos fórmula matemática conocida que relacione los inputs y outputs, en este sentido la predicción es más importante que la explicación. Y necesitan eso sí, grandes cantidades de datos de entrenamiento para que resulten fiables. Como explicamos en un artículo previo, las redes reuronales artificiales fueron desarrolladas por investigadores que trataban de imitar el comportamiento neurofisiológico del cerebro humano.
Otras técnicas
Hay otras técnicas menos populares pero tienen su aplicación también a la hora de hacer análisis predictivos concretos.
El análisis bayesiano se emplea para visión artificial y reconocimiento de patrones. En estos métodos se tratan los parámetros como variables aleatorias y la probabilidad se define como grados de creencia. La probabilidad de que ocurra un evento parte del grado en el que sin tener la certeza crees que el evento es cierto o falso con las evidencias que se conocen. Es decir, partimos de una creencia definida de la distribución probabilista de un parámetro desconocido y a medida que vamos adquiriendo nuevos datos se va actualizando ese grado de creencia.
Series temporales y data mining, basándonos en datos históricos es una de las primeras técnicas que se usan. Recogiendo datos de intervalos temporales como por ejemplo, ventas por meses, llamadas por día, o visitas web por hora, podemos identificar patrones que se repiten constantemente. Este método combina una mezcla de técnicas de data mining tradicional como sampleado, clustering y árboles de decisión, con otras de forecasting con el fin de mejorar las predicciones sobre datos recopilados.
Máquinas de vectores de soporte (support vector machine) son un conjunto de algoritmos de aprendizaje automático supervisado empleados para analizar datos y reconocimiento de patrones.
K-vecinos más cercanos (algoritmo k-nn) es un método no parametrizable de clasificación y regresión que permite predecir valores de un objeto o la clase a la que pertenece basándose en un entrenamiento mediante ejemplos cercanos en el espacio de los elementos.
Ensemble models. Se dice que este método ofrece una de las formas más convincentes para construir modelos predictivos altamente precisos. La disponibilidad de los algoritmos de bagging y boosting permite conseguir un impresionante nivel de precisión. Esta técnica consiste en construir un nuevo modelo entrenando varios modelos similares combinando los resultados para mejorar la precisión, reducir los sesgos, reducir la varianza e identificar el mejor modelo para usar con nuevos datos.
Gradient boosting. El enfoque de boosting consiste en resamplear el dataset varias veces para generar unos resultados que formen una media ponderada del conjunto de datos. Como en la técnica de árboles de decisión, en esta técnica no se hace ninguna suposición sobre la distribución de los datos. De esta manera, es menos propenso a superponer los datos que un árbol de decisión, y si un árbol de decisión se ajusta a los datos bastante bien, el boosting a menudo mejora el ajuste.
Respuesta incremental (modelos net lift y uplift). Esta técnica consiste en modelar el cambio de probabilidad causado por una acción. Son muy utilizados para reducir el churn y para descubrir los efectos de los diferentes programas de marketing.
El razonamiento basado en la memoria es otra técnica k-nn para categorizar y predecir observaciones.
Regresión de mínimos cuadrados parciales es una técnica estadística flexible dentro del grupo de regresión que puede ser aplicada a cualquier tipo y forma de dato. Permite modelar las relaciones existentes entre inputs y outputs incluso cuando los inputs incluyen correlación y ruido, o hay muchos outputs, o hay más inputs que observaciones.
Las tendencias en Big Data han puesto más presión sobre el análisis predictivo para que sea más eficiente y fiable. Esto ha llevado a más proveedores a que incorporen este tipo de análisis en sus productos. Creo que en el futuro seguiremos viendo una adopción de estas tecnologías a medida que la demanda continúe creciendo. En otro artículo veremos en detalle aplicaciones concretas, casos de uso por sectores y herramientas para emplear análisis predictivos en las empresas y organizaciones.


