
¿Qué es Spark?
Apache Spark es un framework de procesamiento en modo código abierto desarrollado en 2009 en el AMPLab de la Universidad de California en Berkeley. El framework fue donado a la Apache Software Foundation en 2013. Spark permite realizar de manera rápida análisis de datos y modelos de desarrollo. Spark permite acceder al conjunto de datos evitando la necesidad de realizar submuestras tal y como hacen entornos tipo R. También da psoporte a trabajar en streaming lo que permite construir modelos en tiempo real con todo el conjunto de datasets. Si la tarea es demasiado grande para un único servidor, la arquitectura permite dividir la tarea en piezas más manejables según las capacidades de hardware que dispongamos en cada momento. Esas piezas de tareas divididas funcionan en modo en memoria a lo largo del cluster de servidores, aprovechando la memoria disponible conjunta del total de máquinas. El procesamiento de Spark está basado en su conjunto elástico de datos distribuidos (Resilient Distributed Dataset o RDD).
¿Porqué Spark se ha impuesto para procesamiento de big data?
En los últimos dos años Spark se ha puesto de moda en el mundo del big data debido a su rendimiento computacional y la amplia gama de librerías como Spark SQL, Spark Streaming, MLlib (machine learning) y GraphX.
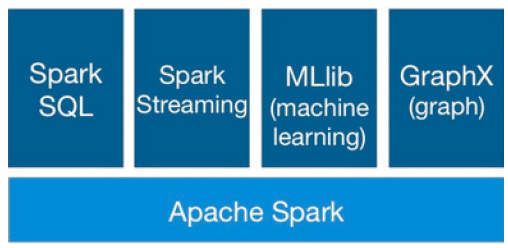 Spark SQL permite el procesamiento de datos estructurados. Permite trabajar con DataFrames, una abstracción de programación, y también puede actuar como motor de consultas SQL distribuido. Spark Streaming permite realizar un procesamiento de datos en tiempo real, escalable, de alto rendimiento, y con tolerancia a fallos. El objetivo de MLlib es hacer práctico, escalable y fácil el machine learning. Consiste en un conjunto de algoritmos y utilidades comunes, como clasificación, regresión, clustering, filtrado colaborativo y reducción de dimensionalidad. GraphX es el componente de Spark para visualizaciones y cálculo gráfico en paralelo.
Spark SQL permite el procesamiento de datos estructurados. Permite trabajar con DataFrames, una abstracción de programación, y también puede actuar como motor de consultas SQL distribuido. Spark Streaming permite realizar un procesamiento de datos en tiempo real, escalable, de alto rendimiento, y con tolerancia a fallos. El objetivo de MLlib es hacer práctico, escalable y fácil el machine learning. Consiste en un conjunto de algoritmos y utilidades comunes, como clasificación, regresión, clustering, filtrado colaborativo y reducción de dimensionalidad. GraphX es el componente de Spark para visualizaciones y cálculo gráfico en paralelo.
Ventajas Spark
Hasta ahora no existía un framework de procesamiento de datos unificado que diera respuesta a todas las demandas. Esta es la ventaja principal de Spark, que permite a las áreas críticas de las empresas beneficiarse de las ventajas que ofrece este marco único. Veamos algunas:
Analítica avanzada
Spark ofrece un framework para realizar análisis avanzados out-of-the-box. Incluye como hemos visto una herramienta para realizar queries rápidamente, una librería de aprendizaje de máquina, un motor de procesamiento de gráficos, y un motor de análisis en datos en en streaming. No hay necesidad de implementar otras herramientas via MapReduce, Spark ya ofrece librerías preconfiguradas, que son más fáciles y rápidas de usar.
Simplicidad
Una de las primeras críticas que se hizo a Hadoop fue que era difícil de usar, requería que los usuarios comprendieran una variedad de complejidades como MapReduce o programación avanzada en Java. Aunque se ha simplificado a la vez que se hacía más potente con cada nueva versión, la queja ha permanecido. Spark fue creado para ser accesible a cualquiera con conocimientos en bases de datos y algo de habilidad de scripting en Python o Scala.
Resultados más rápidos
A medida que el ritmo de los negocios se acelera, también la necesidad para el análisis en tiempo real. Spark ofrece procesamiento in-memory en paralelo, consiguiendo unos resultados múltiples veces más rápidos que otras soluciones que requieren acceso a disco. Los resultados al instante eliminan los retrasos que pueden ralentizar los procesos de negocio e incrementar la analítica necesaria. Otras compañías han creado aplicaciones complementarias para Spark que facilitan una gran cantidad de ampliaciones y mejoras. Lo que se traduce en que los analistas pueden trabajar de forma iterativa, afinando las respuestas más precisas y más completas.
Spark permite a los profesionales de la empresa hacer lo que se supone que deben hacer.
Sin preferencia por distribuidores Hadoop
Todas las distribuciones Hadoop dan soporte ahora a Spark por una razón muy sencilla: Spark es agnóstica en cuanto al distribuidor, lo que significa que el cliente no está atado a un determinado proveedor. Gracias a su naturaleza open-source, las empresas son libres para crear una infraestructura analítica basada en Spark sin necesidad de preocuparse qué ocurrirá si cambian de proveedor Hadoop en un futuro. Si hacen el cambio, pueden llevarse sus analíticas.
Encuesta del ecosistema Spark
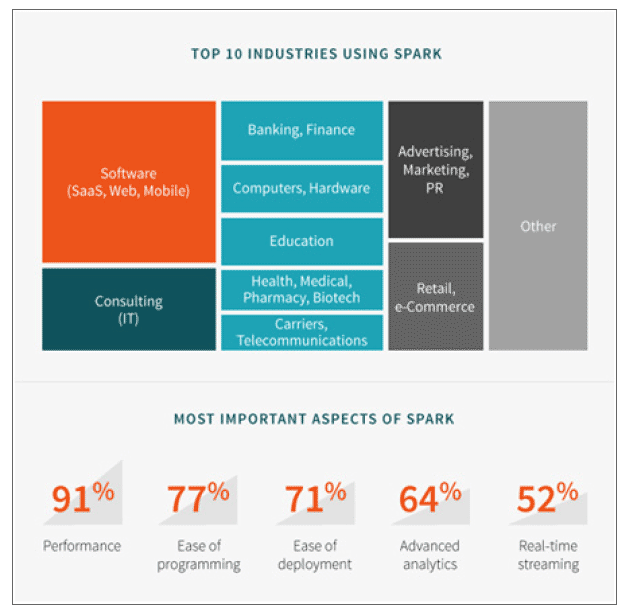
Recientemente Typesafe realizó una encuesta sobre el ecosistema Spark. Algunas claves extraídas del informe sobre cómo se están realizando despliegues Spark en proyectos en las empresas:
[tie_list type=»lightbulb»]
- En cuanto al almacenamiento de datos, un 62% de los encuestados utilizaban HDFS. Casi la mitad, el 46%, estaban utilizando algún tipo de base de datos. El 41% usaba Kafka, y el 29% estaba usando Amazon S3.
- En cuanto a gestión del cluster, el 56% utilizaban una sola instancia de Spark- Un 42% usaban YARN, y el 26% Apache Mesos.
- En cuanto a lenguajes, un 88% usaba Scala, un 44% Java, y un 22% Python.
- En cuanto a roles de usuario, una encuesta de Databricks realizada en 2015, un 41% de los encuestados se consideraba ingeniero de datos, un 22,2% científico de datos, un 17,2% arquitectos de datos, un 10,6% tenían un perfil de gestión de negocio, y un 6,2% estaba relacionado con el entorno académico.
[/tie_list]
Spark, el entorno big data de moda
La cantidad global de datos generados cada día es de 2,5 exabytes. El mercado de big data ha sobrepasado los 27.000 millones USD. Spark es una arquitectura de computación expresamente diseñada para este tipo de crecimiento. En Junio de 2015 IBM anunció que iba a formar un millón de data scientists e ingenieros en Spark. Otras razones por las que la trayectoria ascendente de la arquitectura:
Reinventando MapReduce
Comparándolo con MapReduce, Spark ofrece mayor flexibilidad. MapReduce solamente permite dos operaciones: mapear y reducir. Spark ofrece más de 80 operaciones de alto nivel. MapReduce es ineficiente al manejar determinados algoritmos, por lo que se desarrollaron alternativas para manejar herramientas analíticas interactivas. Spark destaca en la programación de modelos que incorporan iteraciones, interactividad, y streaming.
Uso de HDFS
Spark permite (aunque no obliga a) usar HDFS (Hadoop File System).
Uso de YARN
Spark permite usar el gestor de cargas de trabajo YARN de Hadoop.
Uso eficiente de la memoria
El modelo Hadoop se basa en un modelo en dos etapas MapReduce en disco. Spark es un modelo multi-etapa con primitivas en memoria, lo que permite un tiempo de respuesta de hasta 100 veces para determinadas configuraciones. al permitir a los programas cargar los datos en la memoria del cluster y hacer las consultas repetidamente, Spark está especialmente preparado para algoritmos de machine learning. En estudios de benchmark recientes referentes a almacenamiento en memoria (como instancias HDFS sin disco) Spark superaba a Hadoop en 20 veces.
Spark ofrece workflows de analíticas
Gracias a su librería para machine learning (MLlib), al API para gráficos analíticos (GraphX), el soporte de queries basadas en SQL, y aplicaciones en streaming, Spark se convierte en una plataforma convergente cuando necesitamos hacer analítica seria en big data y usar el código que tengamos escrito en cualquiera de los componentes para hacer nuestro propio workflow analítico.



What do you think?
[…] en mayor parte al avance en la actividad open source. 2015 ha sido sin duda el año de Apache Spark, el framework open source que aprovecha el procesamiento in-memory. Desde entonces, los grandes en Big Data, desde IBM a […]
[…] a la ciencia de datos, el machine learning y plataformas de big data como Spark y Kafka ahora es posible detectar usuarios y comportamientos fraudulentos mediante aprendizaje no […]